lanjut lagi materi scrapingnya pada materi kali ini kita akan coba untuk melakukan scraping satu halaman dengan Beautifulsoup
Scraping Single Quotes
pada studi kasus kali ini kita akan scraping website yang bernama https://quotes.toscrape.com/
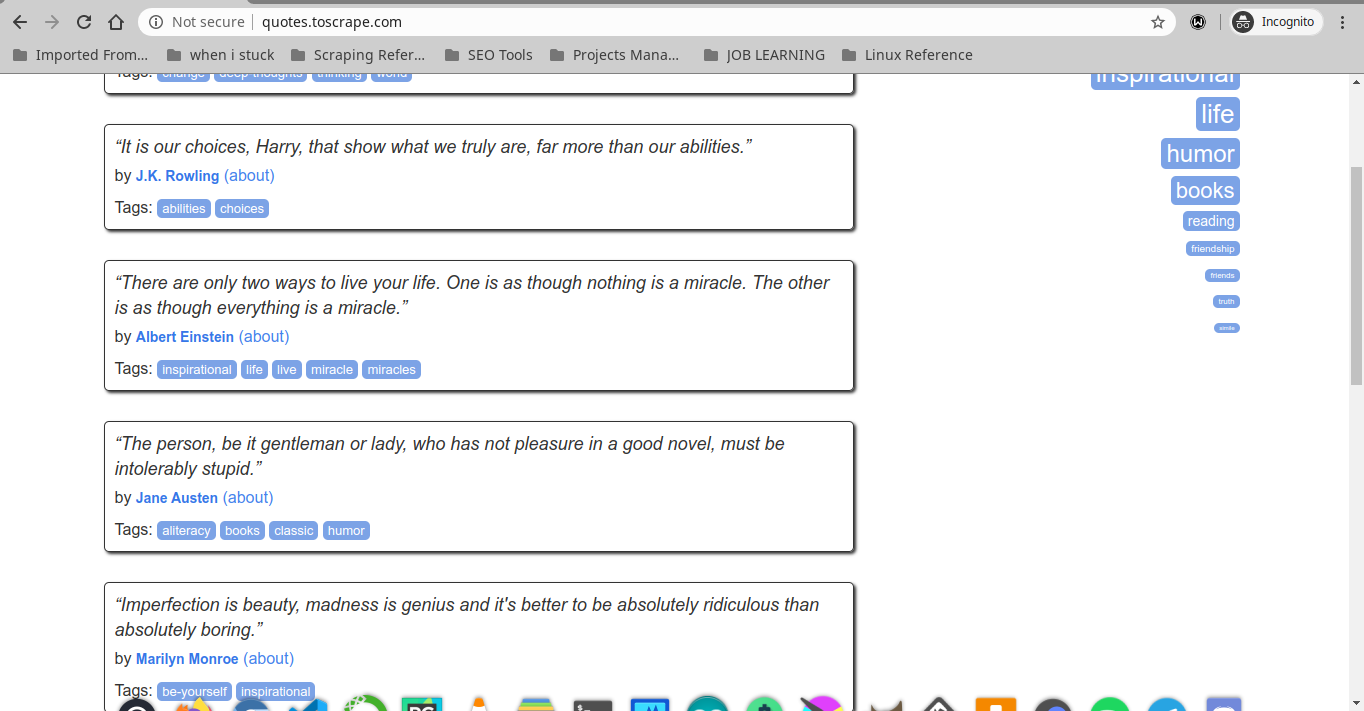
yang dimana website tersebut adalah website yang menyediakan konten-konten quotes yang sangat populer dan salah satu quotes yang memotivasi saya adalah
The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking. by: albert enstein
dan satu lagi
Try not to become a man of success. Rather become a man of value. by albert enstein
Apa yang dibutuhkan
yang dibutuhkan untuk scraping pada studi kasus pada materi ini adalah
Modul requests library
dibutuhkan modul ini untuk melakukan requests terhadap website yang dituju, buat file baru misal bernama quotes.py lalu install module requests dengan pip
pip install requests
langkah selanjutnya import modul requests
# nama file: quotes.py
# materi: scraping satu halaman dengan beautifulsoup
import requests
# masukan url
url = 'http://quotes.toscrape.com'
# requests
req = requests.get(url)
# cetak hasil menggunakan print
print(req)
ini hasilnya
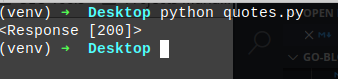
seperti yang kita lihat responya 200 artinya ini OK bisa di Scrap tanpa perlu autentifikasi apapun
modul Bs4 Library
kita membutuhkan fungsi BeautifulSoup() dalam modul Bs4 untuk parsing HTML, cara instalanya bisa menggunakan pip
pip install beautifulsoup4
bisa dilihat disini setelah instalasi import modul
# nama file: quotes.py
# materi: scraping satu halaman dengan beautifulsoup
import requests
from bs4 import BeautifulSoup
# masukan url
url = 'http://quotes.toscrape.com'
# requests
req = requests.get(url)
# parsing html
soup = BeautifulSoup(req.text, 'html.parser')
# print hasil parsing
print(soup.prettify())
hasilnya kita mendapatkan kode HTML dari situs http://quotes.toscrape.com
setelah mendapatkan semua element kita dapat memilah milah dengan fungsi find dan findAll pada module Beautifulsoup
Proses Scraping
untuk mengambil tag tag secara spesifik kita menggunakan fungsi find dan findAll pada module Beautifulsoup yang telah dipelajari pada materi sebelumnya
Mengambil Quotes
untuk mengambil quotes kita perlu menemukan tag html yang dipakai, untuk mengehatui gunakan inspect element

lalu kita ambil dengan findAll() yang akan menghasilkan list
# mengambil semua quotes
quotes_list = soup.findAll('div', attrs={'class':'quote'})
# cek berapa quotes yang kita dapat
print(len(quotes_list))
hasilnya
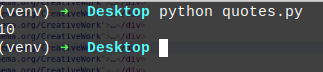
kita mendapatkan 10 quotes sekarang kita akan mengambil isinya kita cari tag yang menampung text quotenya
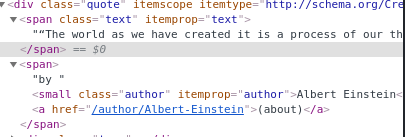
sebelumnya sudah tertampung dalam list jadi tinggal di loop
# mengambil quotes
for quotes in quotes_list:
quote = quotes.find('span', attrs={'class':'text'})
print()
print(quote.text)
maka hasilnya seperti ini
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
“It is our choices, Harry, that show what we truly are, far more than our abilities.”
“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”
“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”
“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”
“Try not to become a man of success. Rather become a man of value.”
“It is better to be hated for what you are than to be loved for what you are not.”
“I have not failed. I've just found 10,000 ways that won't work.”
“A woman is like a tea bag; you never know how strong it is until it's in hot water.”
“A day without sunshine is like, you know, night.”
Mengambil author
sekarang kita akan mengambil tags yang berisi author menggunakan fungsi find() kita cari tagnya

lalu ambil dengan findAll() lalu di loop
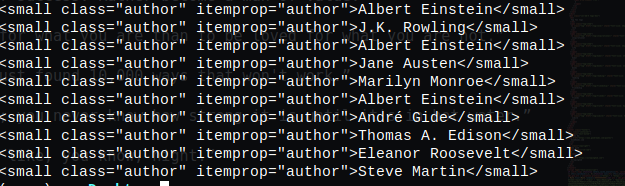
# mengambil author
author_list = soup.findAll('small', attrs={'class':'author'})
for author in author_list:
print(author)
tambahkan .text untuk mengambil valuenya saja
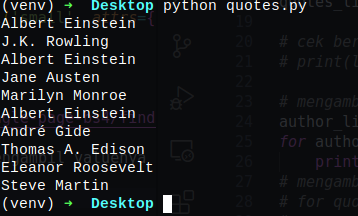
# mengambil author
author_list = soup.findAll('small', attrs={'class':'author'})
for author in author_list:
print(author.text)
Mengambil tags
kita akan mengambil tags tambahkan kode berikut
tags = [tag.text for tag in soup.find('div', class_='tags').find_all('a', class_='tag')]
print(tags)
Final Code
ini final code materi kali ini
# nama file: quotes.py
# materi: scraping satu halaman dengan beautifulsoup
import requests
from bs4 import BeautifulSoup
# masukan url
url = 'http://quotes.toscrape.com'
# requests
req = requests.get(url)
# parsing html
soup = BeautifulSoup(req.text, 'html.parser')
# mengambil semua quotes
quotes_list = soup.findAll('div', attrs={'class':'quote'})
# cek berapa quotes yang kita dapat
# print(len(quotes_list))
# mengambil author
# author_list = soup.findAll('small', attrs={'class':'author'})
# for author in author_list:
# print(author.text)
# mengambil quotes
# for quotes in quotes_list:
# quote = quotes.find('span', attrs={'class':'text'})
# print()
# print(quote.text)
# mengambil tags
tags = [tag.text for tag in soup.find('div', class_='tags').find_all('a', class_='tag')]
print(tags)
semoga bermanfaat dan selamat mencoba