pada tutorial ini kita belajar mengimplementasikan bagaimana penggunaan Beautiful Soup
Studi Kasus
misalnya kita mempunyai kode HTML seperti ini
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
pastikan sudah menginstall beautifulsoup dengan perintah
pip install Beautifulsoup4
library ini dapat dicari di pypi.org
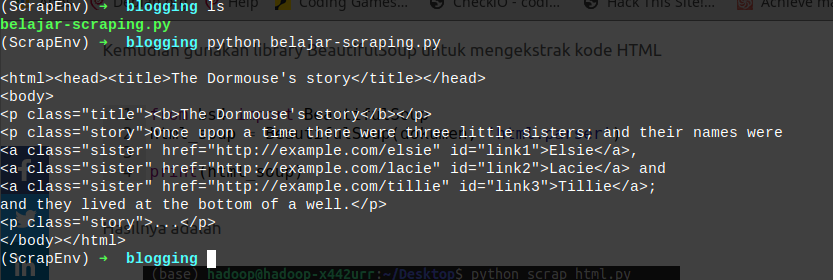
setelah melakukan instalasi coba gunakan library BeautifulSoup, contoh
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup)
hasilnya akan seperti ini
Mengenal Fungsi find() dan findAll()
dalam library BeautifulSoup terdapat dua fungsi yang paling banyak dipakai yaitu fungsi find() dan findAll()
Fungsi find()
digunakan untuk mengambil potongan kode HTML atau kode HTML secara spesifik (jika terdapat tag HTML atau class atau id yang sama lebih dari satu maka tag yang diambil adalah tag yang paling atas di halaman HTML) contoh
link = soup.find('a')
print(link)
hasilnya akan seperti ini

Mengambil nilai dengan atribut tertentu
contoh jika ingin mengambil nilai dari tag ‘a’ dengan nama class atau id tertentu bisa seperti ini
lacie = soup.find('a', attrs={'id':'link2'})
print(lacie)
hasilnya

jika mengambil textnya saja tambahkan .text seperti ini
lacie = soup.find('a', attrs={'id':'link2'}).text
print(lacie)
hasilnya

Fungsi findAll()
fungsi ini untuk mengambil semua tag yang sama, dan hasilnya akan dikembalikan atau di return list contoh
semua_link = soup.findAll('a')
print(semua_link)
hasilnya

untuk extract data url yang telah di temukan bisa menggunakan perulangan, contoh
semua_link = soup.findAll('a')
for i in semua_link:
print(i.get('href'))
hasilnya

sebenarnya masih banyak fungsi yang dapat dipelajari tapi fungsi yang paling sering dan paling unum digunakan adalah fungsi find() dan findAll(), berikut kode lengkap yang telah dibuat pada materi ini
# nama file: belajar-scraping.py
# materi: mengenal find() dan findAll()
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
link = soup.find('a')
lacie = soup.find('a', attrs={'id':'link2'}).text
elsie = soup.find(id='link1')
print(elsie.text)
semua_link = soup.findAll('a')
for i in semua_link:
print(i.get('href'))
# print(semua_link)
# print(lacie)