Apa itu Web Scraping
kamu dapat mengetahui gambaran secara kasar tetang web scraping melalui kasus semacam ini misalnya kamu ungin mengetahui siapa matematikawan terpopuler disini kamu akan belajar nagaimana mengambil suatu data dari halamat web ke dalam bentuk yamg diinginkan misanya format json atau csv.
Mengenal Komponen utama pada Halaman Web
sebuah website biasanya terdiri dari 3 komponen dasar seperti
- HTML (Hypertext Markup Language)
- CSS (Cascading Style Sheet)
- JS (Javascript)
HTML bisa dibilang ini adalah komponen utama sebuah website seperti paragraf dan tag tag lainya CSS kalo ini digunakan untuk mempercantik tampilan pada sebuah website. Javascript ini bisa digunakan sebagai backend maupun frontend pada sebuah website supaya lebih interaktif saat dilihat dan digunakan oleh user
Web Scraping Starter Pack
web scraping dapat dilakukan dengan menggunakan bahasa pemrograman Python dengan memanfaatkan tools tools tertentu seperti
- request packages
- BeautifulSoup
Inspect Element Trick
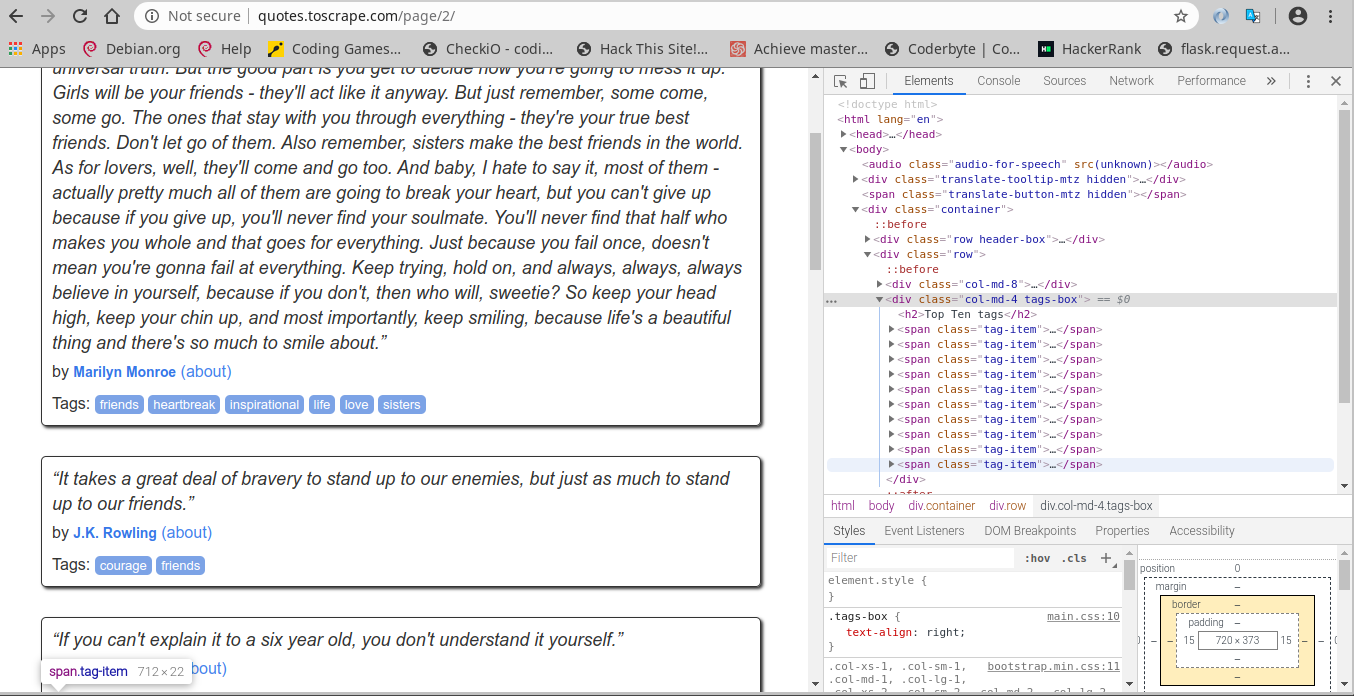
untuk mengetahui kode yang dari suatu website dapat dilakukan dengan cara inspect element dalam studi kasus ini saya akan inspect element web http://quotes.toscrape.com/page/2/ untuk inspect element bisa tekan
Ctrl + Shift + I
Highlight Komponen secara spesifik
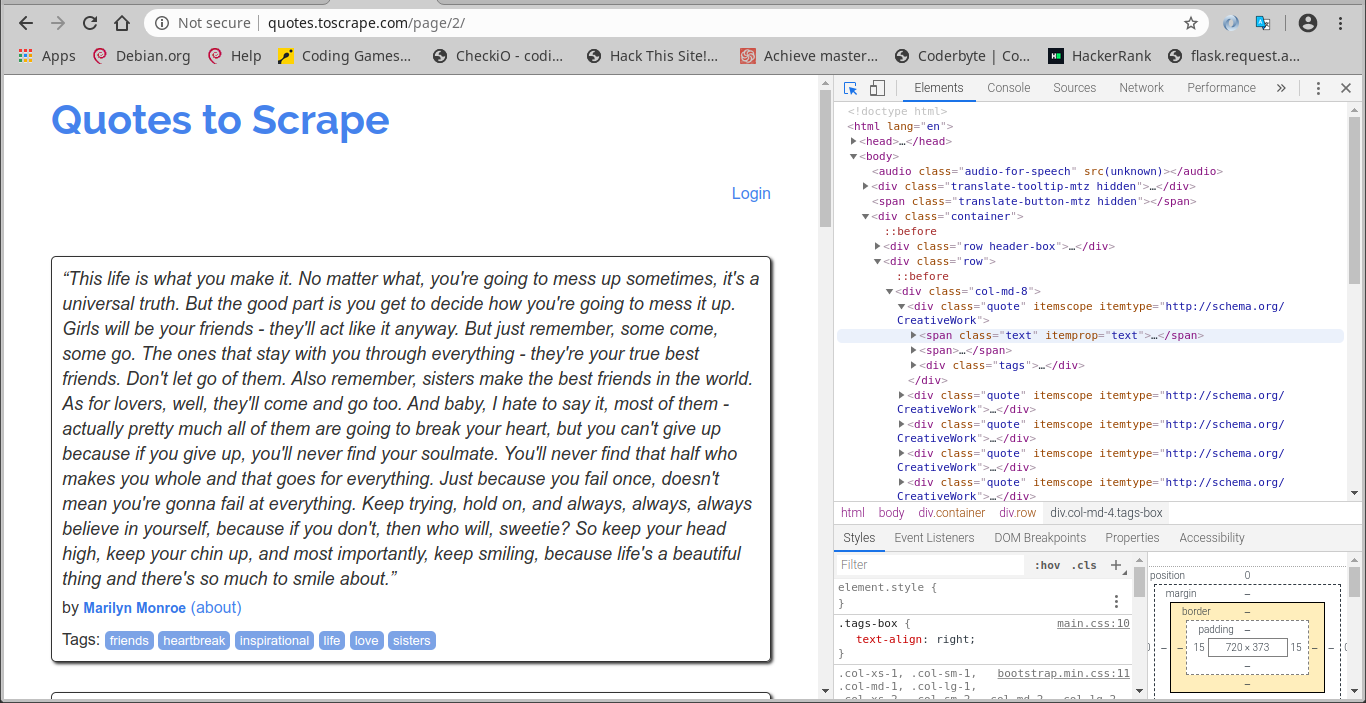
kita dapat melakukan highlight pada komponen website secara spesifik dengan menekan tombol
Ctrl + Shift + C
Studi Kasus Scraping Quotes to Scrap
sekarang kita akan coba scraping website quotes langkah pertama yang harus dilakukan adalah:
- Install Request
pip install request
- install bs4
pip install beautifulsoup4
Langkah Scraping
buat file misal quotes.py
# import modul yang dibutuhkan
import requests
# input url
url = 'http://quotes.toscrape.com/page/1'
req = requests.get(url)
# print kode html yang didapat request dari url
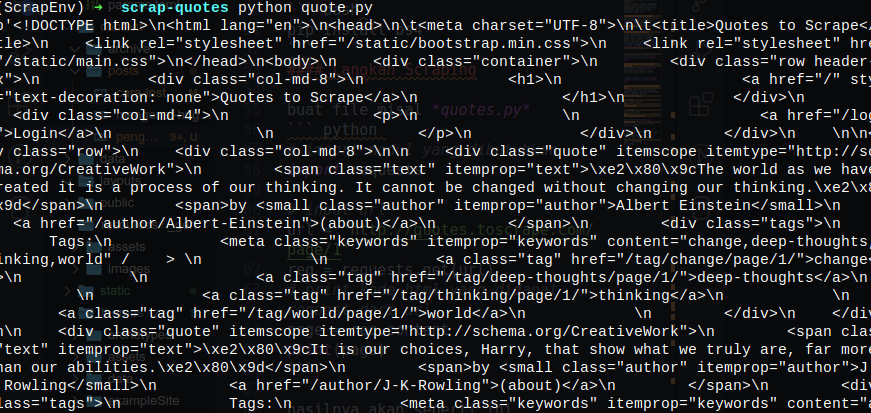
page = req.content
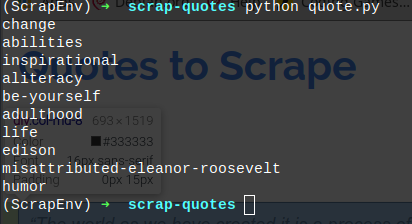
print(page)
hasilnya akan seperti ini
Extract Halaman dengan Beautiful Soup
Setelah menginstall BeautifulSoup pada langkah sebelumnya kita gunakan library ini untuk mengambil tag tag dan isi website seperti author, content, tag dan lain sebagainya pada element HTML buka dan edit kembali file quotes.py
# import modul
import requests
from bs4 import BeautifulSoup as b
url = 'http://quotes.toscrape.com/page/1'
req = requests.get(url)
# proses extract
soup = b(req.content, 'html.parser')
quote = soup.find('span',class_='text').text
print('Kata-kata',quote)
# author
author = soup.find('small', class_='author').text
print('Pencipta', author)
hasilnya seperti ini

contoh menggunakan findAll() edit file quotes.py
# mengenal fungsi findall
quotes = soup.findAll('div', attrs={'class':'quote'})
for quote in quotes:
tags = quote.find('a', class_='tag').text
print(tags)
hasilnya seperti ini